Commodore PET/Reparatur

Info
An English translation of this article is available here: https://s3lph.me/restoring-a-commodore-cbm-3016.html
Wir sind kürzlich in den Besitz eines Commodore PET/CBM 3016 gekommen, Baujahr zwischen 1978 und 1980. Beim ersten Anschalten wurden wir allerdings von einem Bildschirm voll Zufallsdaten begrüsst:
-
 Bildscherm des CBM 3016 gefüllt mit zufälligen Zeichen.
Bildscherm des CBM 3016 gefüllt mit zufälligen Zeichen.

Eine kurze Internetsuche nach diesem Problem hat ergeben, dass die häufigste Ursache für dieses Problem defekte ROM-Chips sind.
Die Memory- und ROM-Map
Die in der PET- / CBM-Reihe verwendete MOS 6502-CPU hat einen 8-Bit Datenbus und 16-Bit Adressbus.
Gemäss Schaltplänen des PET, die online zu finden sind, werden die obersten 4 dieser 16 Bit verwendet, um zu entscheiden, mit welchem Gerät die CPU kommuniziert:
Die gesamte untere Hälfte des Adressraums ($0000:$7fff) ist dem DRAM zugeordnet. Da unser Modell (3016) aber nur mit 16KiB RAM ausgestattet ist, wird nur der Adressbereich $0000:$3fff tatsächlich verwendet. Darauf folgt der Videopuffer im Bereich $8000:$8fff, und darauf mehrere 4KiB ROM-Chips von $9000:9fff bis $f000:$fff. Auch hier wird nur ein Teil des Adressbereichs verwendet; der Bereich $9000:$bfff ist leeren DIP-Sockeln zugeordnet, in die durch die Benutzer*in Software-ROMs hinzugefügt werden können.
Das Betriebssystem des PET ist in 4 ROMs abgelegt:
$c000:$cfff: BASIC-Editor/-Interpreter/-Funktionen, Teil 1$d000:$dfff: BASIC-Editor/-Interpreter/-Funktionen, Teil 2$e000:$e7ff: Input/Output-Verarbeitung. Die oberen 2KiB ($e800:$efff) sind direkt mit der Peripherie (z.B. der Tastatur) verbunden.$f000:$ffff: Der KERNAL ("Kernel", aber mit einem Schreibfehler während der Produktentwicklung).
Zudem gibt es noch ein weiteres 2KiB-ROM, auf welchem der Zeichensatz gespeichert ist, der auf dem Bildschirm angezeigt werden kann. Dieses ROM ist allerdings nicht über den Adressbus der MOS 6502 adressierbar, sondern wird direkt von der Hardware verwendet, die sich um das Rendern des Bildschirms kümmert.
Wir haben alle ROMs aus dem PET entfernt und mit unserem MiniPRO TL866A programmer ausgelesen:
minipro -yp 27C32A@DIP24 -r basic1.bin minipro -yp 27C32A@DIP24 -r basic2.bin minipro -yp 27C32A@DIP24 -r kernal.bin minipro -yp M2716@DIP24 -r io.bin minipro -yp M2716@DIP24 -r chars.bin
Über die Lebensdauer der PET-Reihe wurden verschiedene Versionen von KERNAL+BASIC in den PETs verbaut. Wir wussten daher nicht, wie unsere ROM-Dumps eigentlich aussehen sollten. Glücklicherweise haben wir Dumps der meisten dieser Versionen online gefunden, und nur eine dieser Versionen stimmt mit unseren Dumps überein: Die Version BASIC 2.0.
Zumindest die meisten Dumps stimmen überein. Der Inhalt des IO-ROMs und des ersten BASIC-ROMs hatte nicht annährend Ähnlichkeit mit den Online-Dumps. Nachdem wir dieses ROMs erneut ausgelesen hatten, bekamen wir komplett andere Daten zurück. Nach mehrmaliger Wiederholung stellte sich heraus, dass diese beiden ROMs komplett defekt waren und weitestgehend zufällige Daten lieferten.
Erstellung neuer ROMs
Wir haben ein paar pinout-kompatible EPROMs gefunden, die wir als Ersatz verwenden wollten. Allerdings haben wir nach dem Löschen mit unserem UV-Erase festgestellt, dass unser Programmer nicht in der Lage ist, die Programmierspannung von 25V zu liefern. Wir haben zwar versucht, die Programmierspannung mit einer externen Stromversorgung zu liefern, und hatten beschränkten Erfolg (heisst: wir konnten einzelne Bits schreiben), aber konnten nie einen ganzen Schreibzyklus abschliesen.
Daher haben wir uns nach Alternativen umgeschaut und mehrere Rails einmalig programmierbarer AT27C040-PROMs im PLCC-Formfaktor gefunden. Diese PROMs verfügen über ganze 512 KiB Speicher. Unser Plan war, die untersten 2 resp. 4 KiB zu verwenden, und die nicht verwendeten Adresspins auf GND zu verdrahten. Wir haben ein Adapter-PCB von PLCC32 zu DIP24 entworfen, das sowohl das 2KiB- als auch das 4KiB-Pinout unterstützt.
-
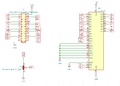 Schaltplan des PLCC32-zu-DIP24 Adapter-PCBs, um einen AT27C040 als Ersatz für die defekten PET-ROMs zu verwenden.
Schaltplan des PLCC32-zu-DIP24 Adapter-PCBs, um einen AT27C040 als Ersatz für die defekten PET-ROMs zu verwenden.

Mit der Lötbrücke im Schaltplan kann zwischen der 2K- und 4K- Version gewählt werden; in der 4K-Ausführung ist der OE-Pin («Output Enable») dauerhaft auf logisch 0 gezugen, in der 2K-Ausführung, ist er mit A11 (dem 12. Adressbit) verbunden: Wenn dieses Bit 1 ist, wird der Ausgang deaktiviert und auf hochohmig gesetzt, um die Kommunikation zwischen CPU und Peripherie nicht zu stören, die in der oberen Hälfte des $e000:$efff-Adressraums anliegt.
Schlussendlich haben wir aber (zumindest anfangs) eine unschöne, aber einfachere Lösung gewählt: Anstatt PCBs zu produzieren, haben wir die PROMs mit kurzen Drähten an DIP-Sockel gelötet und. Nachdem wir diese Ersatz-ROMs in die Sockel des PETs eingesetzt hatten, konnten wir zumindest einen kleinen Fortschritt beoubachten: Der Bildschirm war immer noch mit zufälligen Zeichen gefüllt, aber ein paar Sekunden nach dem Start wurde der gesamte Bildschirminhalt gelöscht, danach passierte allerdings nichts mehr. Es scheint, als würde die CPU irgendetwas tun, aber nicht das richtige.
-
 Die Ersatz-ROMs in ihren Sockeln.
Die Ersatz-ROMs in ihren Sockeln.

Suche nach CPU-Fehlern
Um herauszufinden, was die CPU tatsächlich tat, haben wir einen Logic Analyzer an den Adressbus angeschlossen und jede Adresse aufgezeichnet, die zwischen dem Start und dem Leeren des Bildschirms am Bus angelegt war. Eine Sache, die sofort offensichtlich wurde, war, dass auf dem Adressbus keinerlei Aktivität mehr stattfand, nachdem der Bildschirm geleert wurde. Da die MOS 6502 CPU im Betrieb mindestens alle 1-6 Zyklen eine Instruktion aus dem ROM lädt, schien die CPU komplett angehalten zu haben. Dies tritt üblicherweise nur auf, wenn eine ungültige HCF-Instruktion ausgeführt wird.
Daher haben wir uns genauer angeschaut, welche Instrukionen die CPU direkt vor dem Einfrieren geladen hatte. Wir haben den Disassember dxa64 verwendet, um die ROM-Dumps in 6502-Assembly zu übersetzen und zu verstehen, welche Instruktionen an welchen Adressen stehen.
Und tatsächlich stellte sich heraus, dass die zuletzt von Adresse $f4e0 geladene und ausgeführte Instruktion, $d2, eine ungültige Instruktion ist, die die CPU anhält.
Gemäss dem Disassembly befindet sich an dieser Adresse allerdings gar keine Instruktion, sondern eine Zeropage-Adresse, die als Argument einer vorigen Instruktion verwendet wird.
Ein paar Zyklen vorher konnten wir etwas Vielversprechendes finden: Eine rts-Instruktion (Return from Subroutine) wurde geladen, gefolgt von zwei Zugriffen aus die Stack-Page ($01fe:$01ff): Die Rücksprung-Adresse.
Danach wurde die nächste Instruktion von der Adresse $f4d8 geladen.
Das Seltsame hieran war, dass ein rts immer nur an eine Adresse springen sollte, vor der eine dazugehörige jsr-Instruktion (Jump to Subroutine) steht. Diese war hier jedoc nicht vorhanden.
-
 Ein Logic Analyzer am Adressbus und der Φ₂-Clock des MOS 6502 angeschlossen.
Ein Logic Analyzer am Adressbus und der Φ₂-Clock des MOS 6502 angeschlossen. -
 Screenshot der Logic Analyzer-Software; die dekodierten Speicheradressen werden oberhalb angezeigt.
Screenshot der Logic Analyzer-Software; die dekodierten Speicheradressen werden oberhalb angezeigt.


Nun war klar, dass die CPU zu einer falschen Adresse springt, was defekten RAM nahelegt.
Um mehr darüber herauszufinden, haben wir in der Aufzeichnung des Logic Analyzers noch weiter zurückgesucht, und eine passende jsr-Instruktion an Adresse $fcd5 gefunden.
Gemäss Spezifikation der jsr-Instruktion müsste die Adresse $fcd7 auf den Stack gseschrieben werden (Adresse der jsr-Instruktion + 2).
Vergleicht man diese mit der Adresse, die tatsächlich vom Stack zurückgelesen wurde, $f6d7 (Returnadresse - 1), fällt auf, dass sich diese Adressen in genau einem Bit unterscheiden, was den Verdacht auf fehlerhaften RAM weiter erhärtet:
$fcd7 = 1111 1100 1101 0111
$f4d7 = 1111 0100 1101 0111
^
Suche nach defektem RAM
Um das fehlerhafte RAM-Modul zu finden, mussten wir erst das Layout der RAM-Chips verstehen.
Der DRAM des CBM 3016 besteht aus 16 MOSTEK MK4108-Modulen im DIP16-Formfaktor, organisiert in 2 Gruppen von 8 Chips. Gemäss dem Datenblatt des MK4108/4116 (Seiten 140ff) speichert jeder Chip 8192 einzelne Bits. Mithilfe eines Multimeters haben wir das folgende Memory-Layout herausgefunden:
D0 D1 D2 D3 D4 D5 D6 D7
__ __ __ __ __ __ __ __
| | | | | | | | | | | | | | | |
| | | | | | |\/| | | | | | | | |
$0000:$1fff | | | | | | |/\| | | | | | | | |
|__| |__| |__| |__| |__| |__| |__| |__|
__ __ __ __ __ __ __ __
| | | | | | | | | | | | | | | |
| | | | | | | | | | | | | | | |
$2000:$3fff | | | | | | | | | | | | | | | |
|__| |__| |__| |__| |__| |__| |__| |__|
VVVV Vorderseite des PET VVVV
Da das fehlerhafte Bit an der 4. Position war (vom least-significant bit des oberen Bytes aus gezählt), und der CPU-Stack (von wo aus die falsche Adresse gelesen wurde) im Adressbereich $0100:$01ff liegt, müsste der fehlerhafte Chip das D3-Modul in der hinteren Reihe sein, oben mit einem X markiert. Um dies zu bestätigen, haben wir den Chip mit dem D3-Chip der vorderen Reihe getauscht - zum Glück sind diese nicht fest verlötet. Und tatsächlich startete der PET und zeigte den BASIC-Interpreter. Es wurden aber statt der erwarteten 15K freiem RAM nur 7K angegeben:
-
 Der CBM 3016 startet in den BASIC-Interpreter. Es werden allerdings nur 7K freier Seicher angezeigt, anstatt der erwarteten 15K.
Der CBM 3016 startet in den BASIC-Interpreter. Es werden allerdings nur 7K freier Seicher angezeigt, anstatt der erwarteten 15K.

Jetzt, da zumindest ein Teil des Speichers funktionsfähig war, haben wir ein Speichertest-Programm geschrieben. Wir haben das Programm direkt in 6502-Assembly geschrieben, und auf einen PROM geschrieben, der in den $f000:$ffff-Sockel gesteckt wird, der normalerweise vom KERNAL-ROM verwendet wird. Dies haben wir aus mehreren Gründen getan:
- Der KERNAL verwendet den Speicherbereich
$0000:$2000selbst. Ein Memtest-Programm, dass nach dem KERNAL geladen würde, würde diesen Bereich ebenfalls überschreiben. - Der gesamte Speicherbereich
$0100:$01ffwird als Stack verwendet. Allerdings sollte dieser Bereich ebenfalls getestet werden. Dadurch, dass wir direkt in Assembly geschrieben haben, konnten wir jegliche implizite Verwendung des Stacks, z.B. durch Funktionsaufrufe, sowie andere implizite Speicherzugriffe vermeiden.
Das Memtest-Programm kommt für den eigenen Zustand mit 7 Byte Speicher in der Zeropage aus; diese 7 Byte werden rudimentär getestet, danach kann der gesamte restliche Speicher sehr ausführlich getestet werden. Um bei der Entwicklung des Memtests besser testen zu können (und um nicht einen Haufen Einmal-PROMs zu verschwenden), haben wir einen 6502-Emulator zur Hand genommen, die Memory-Map des PET auf diesem abgebildet und simulierte Speicherfehler erzeugt. Das Memtest-Programm gibt es auf unserem Git-Server.
Nachdem wir die 16K-Version des Memtests auf einen PROM geschrieben und diesen in unserem PET gestartet hatten, fand dieser Speicherfehler in der gesamten oberen Hälfte des DRAM-Adressraums, $2000:$3fff. Die meisten dieser Fehler wurden tatsächlich durch das bereits entdeckte defekte Speichermodul verursacht. Allerdings gab es auch ein paar weitere Fehler, die an einem anderen Bit auftraten und daher von einem anderen Modul veursacht werden.
-
 Ein Memtest auf dem CBM 3016 zeigt Fehler in der gesamten oberen Hälfte des DRAM-Adressraums. Jeder Fehlereintrag besteht aus der Adresse, dem geschriebenen Wert an diese Adresse und dem aus dem RAM zurückgelesenen Wert.
Ein Memtest auf dem CBM 3016 zeigt Fehler in der gesamten oberen Hälfte des DRAM-Adressraums. Jeder Fehlereintrag besteht aus der Adresse, dem geschriebenen Wert an diese Adresse und dem aus dem RAM zurückgelesenen Wert.

Ersatz des defekten RAMs
Wir sind zunächst davon ausgegangen, dass es relativ schwierig sein würde, kompatible RAM-Module zu finden. Allerdings haben wir in unserem Space einen C64 gefunden, der bereits ausgeschlachtet wurde, um andere C64 zu reparieren. Daher haben wir uns kurzerhand an dessen RAM-Modulen bedient. Der C64 hat nur 8 Speichermodule, die allerdings jeweils 64 Kib gross sind. Diese Micron MT4264-15-Chips sind weitestgehend pin-kompatible zu den MK4108/4116: Sie verfügen über einen zusätzlichen Adresspin, haben aber weniger Pins für die Stromversorgung (nur einmal 5V, anstatt wie beim MK4108 -5V, +5V und +12V). Der Adapter-Sockel hierfür war daher sehr einfach zu bauen; deutlich schwieriger war dabei das Auslöten der DIP24-RAM-Module aus dem PCB des C64 - im Gegensatz zum PET sind diese dort fest verlötet.
-
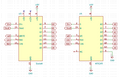 Schaltplan des Pinout-Adapters, um MT4264-Chips in Sockeln für MK4108/4116 DRAMs zu verwenden.
Schaltplan des Pinout-Adapters, um MT4264-Chips in Sockeln für MK4108/4116 DRAMs zu verwenden. -
 Der Ersatz-RAM im Adapter-Sockel.
Der Ersatz-RAM im Adapter-Sockel.


Nachdem wir das defekte RAM-Modul ersetzt hatten, haben wir einen weiteren Memtest gestartet, und es traten keine Fehler mehr auf. Das hatte uns etwas überrascht, da wir ja eigentlich noch einen weiteren Speicherdefekt erwartet hatten. Anschliessend haben wir den KERNAL-ROM wieder eingesetzt, und endlich startete der PET mit seinen vollen 16 KiB Arbeitsspeicher:
-
 Der CBM 3016 BASIC-Interpreter, nun sind 15K freier Speicher verfügbar.
Der CBM 3016 BASIC-Interpreter, nun sind 15K freier Speicher verfügbar.
